1.5 Data Science Roles
As companies learn about using data to help with the business, there is a continuous specialization of different data science roles. As a result, the old “data scientist” title is fading, and some other data science job titles are emerging. In the past, misunderstanding data science’s fundamental work led to confusing job postings and frustrations for stakeholders and data scientists. Stakeholders were frustrated that they weren’t getting what they expected, and data scientists were frustrated that the company didn’t appreciate their talent.
On the one hand, the competitive hiring market has pushed organizations to have a streamlined and transparent interview process. They must clarify the role and responsibilities, tool usage, and daily work for the candidates to understand what the role entails. Role clarity is critical for building a career path and retaining data science talents. As a result, we are glad to see the job definition within an organization has improved dramatically.
On the other hand, however, there is title inconsistency across different companies or industries, especially for the analytical roles (i.e., data analysts and data scientists). An analyst at one company may be close to a data scientist at another company.
The following table shows a list of data science job titles. Some are relatively new, and others have been around for some time but are now well-defined. In the rest of this section, we will illustrate different data science roles, backgrounds, and required skills in general. The title and profile combination in the following text may not represent the truth of a particular company. You may find the description of a role under a different title.
| Role | Skills |
|---|---|
| Data infrastructure engineer | Go, Python, AWS/Google Cloud/Azure, logstash, Kafka, and Hadoop |
| Data engineer | spark/scala, python, SQL, AWS/Google Cloud/Azure, Data modeling |
| BI engineer | Tableau/looker/Mode, etc., data visualization, SQL, Python |
| Data analyst | SQL, basic statistics, data visualization |
| Data scientist | R/Python, SQL, basic applied statistics, data visualization, experimental design |
| Research scientist | R/Python, advanced statistics, experimental design, ML, research background, publications, conference contributions, algorithms |
| Applied scientist | ML algorithm design, often with an expectation of fundamental software engineering skills |
| Machine learning engineer | More advanced software engineering skillset, algorithms, machine learning algorithm design, system design |
The above table shows some data science roles and common technical keywords in job descriptions. Those roles are different in the following key aspects:
- How much business knowledge is required?
- Does it need to deploy code in the production environment?
- How frequently is data updated?
- How much engineering skill is required?
- How much math/stat knowledge is needed?
- Does the role work with structured or unstructured data?
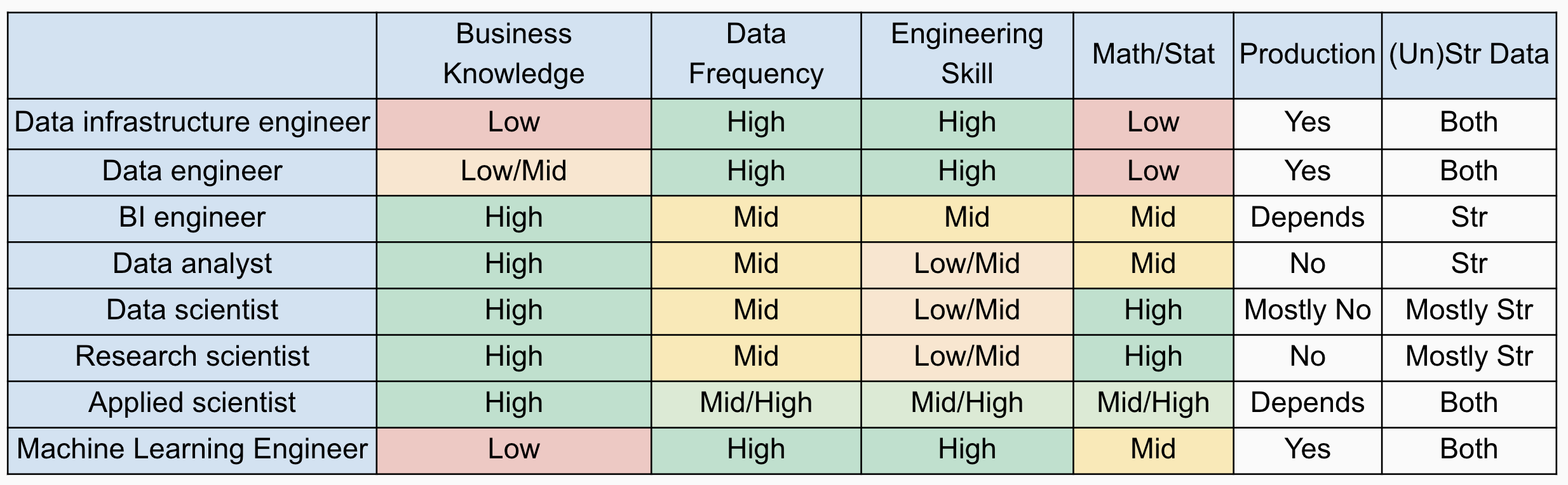
Different roles in data science and the skill requirements
Data infrastructure engineers work at the beginning of the data pipeline. They are software engineers who work in the production system and usually handle high-frequency data. They are responsible for bringing data of different forms and formats and ensuring data comes in smoothly and correctly. They work directly with other engineers (for example, data engineers and backend engineers). They typically don’t need to know the data’s business context or how data scientists will use it. For example, integrate the company’s services with AWS/GCP/Azure services and set up an Apache Kafka environment to stream the events.
People call a storage repository with vast raw data in its native format (XML, JSON, CSV, Parquet, etc.) a data lake (figure 1.5). As the number of data sources multiplies, having data scattered in various formats prevents the organization from using the data to help with business decisions or building products. That is when data engineers come to help.
Data engineers transform, clean, and organize the data from the data lake. They commonly design schemas, store data in query-able forms, and build and maintain data warehouses. People call this cleaner and better-organized database data mart (figure 1.5) which contains a subset of data for business needs. They use technologies like Hadoop/Spark and SQL. Since the database is for non-engineers, data engineers need to know more about the business and how analytical personnel uses the data. Some may have a basic understanding of machine learning to deploy models developed by data/research scientists.
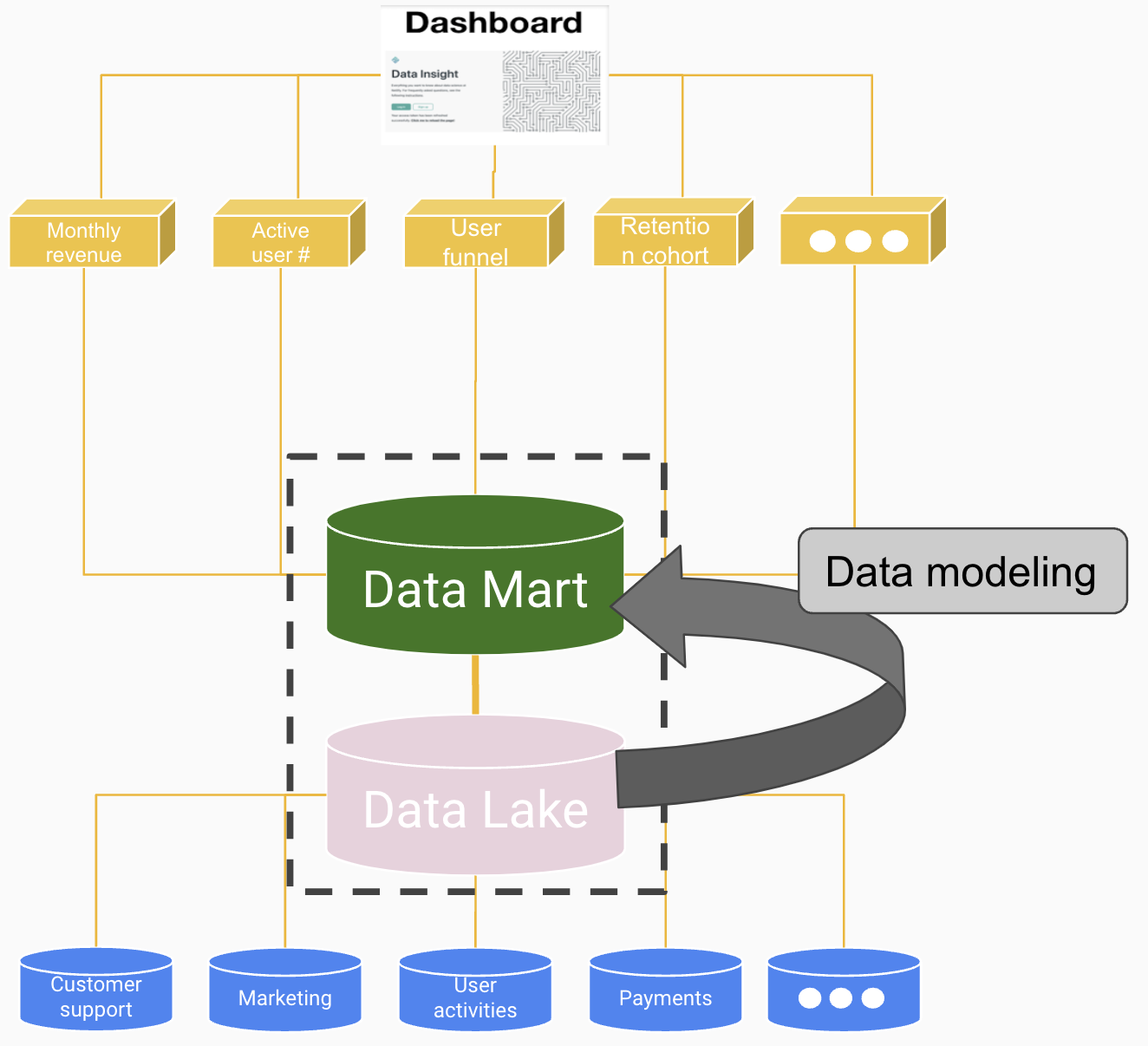
FIGURE 1.5: Data lake (a focused version of a data warehouse that contains a subset of data for business needs) and data mart (a storage repository that cheaply stores a vast amount of raw data in its native format (XML, JSON, CSV, Parquet, etc.))
Business intelligence (BI) engineers and data analysts are close to the business, so they need to know the business context well. The critical difference is that BI engineers build automated dashboards, so they are engineers. They are usually experts in SQL and have the engineering skill to write production-level code to construct the later steam data pipeline and automate their work. Data analysts are technical but not engineers. They analyze ad hoc data and deliver the results through presentations. The data is, most of the time, structured. They need to know coding basics (SQL or R/Python), but they rarely need to write production-level code. This role was mixed with “data scientist” by many companies but is now much better refined in mature companies.
The most significant difference between a data analyst and a data scientist is the requirement of mathematics and statistics. Most data scientists have a quantitative background and do A/B experiments and sometimes machine learning models. Data analysts usually don’t need a quantitative background or an advanced degree. The analytics they do are primarily descriptive with visualizations. They mainly handle structured and ad hoc data.
Research scientists are experts who have a research background. They do rigorous analysis and make causal inferences by framing experiments and developing hypotheses, and proving whether they are true or not. They are researchers that can create new models and publish peer-reviewed papers. Most of the small/mid companies don’t have this role.
Applied scientist is the role that aims to fill the gap between data/research scientists and data engineers. They have a decent scientific background but are also experts in applying their knowledge and implementing solutions at scale. They have a different focus than research scientists. Instead of scientific discovery, they focus on real-life applications. They usually need to pass a coding bar.
In the past, some data scientist roles encapsulated statistics, machine learning, and algorithmic knowledge, including taking models from proof of concept to production. However, more recently, some of these responsibilities are now more common in another role: machine learning engineer. Often larger companies may distinguish between data scientists and machine learning engineer roles. Machine learning engineer roles will deal more with the algorithmic and machine learning side and strongly emphasize software engineering. In contrast, data scientist roles will emphasize analytics (as with data analysts) and statistics, such as significance testing and causal inference.