2.2 What is Data Model?
Data model is what we use to organize information for multiple tables and how they relate to each other together. This helps tremendously in providing structure to the information in the system. Usually a data model represents a business process and it also helps you understand a business process. As a data scientist, you often need to work with a business person in understanding the data and how it fits together. But at the same time, the business person will learn a lot from the data modeller to better understand how their business actually works together by seeing the data and how it interacts with each other.
The data model here is not predictive model which a data scientist often build. It is a way the tables are represented and organized in a database. One thing to remember is that a data model should always represent a real world problem as closely as possible. There are couple different types of models, and there has been an evolution of data models.
The evolution of data model traces back to 1960s. There’s been hierarchical, network, relational, entity, relational somatic, and NoSql.
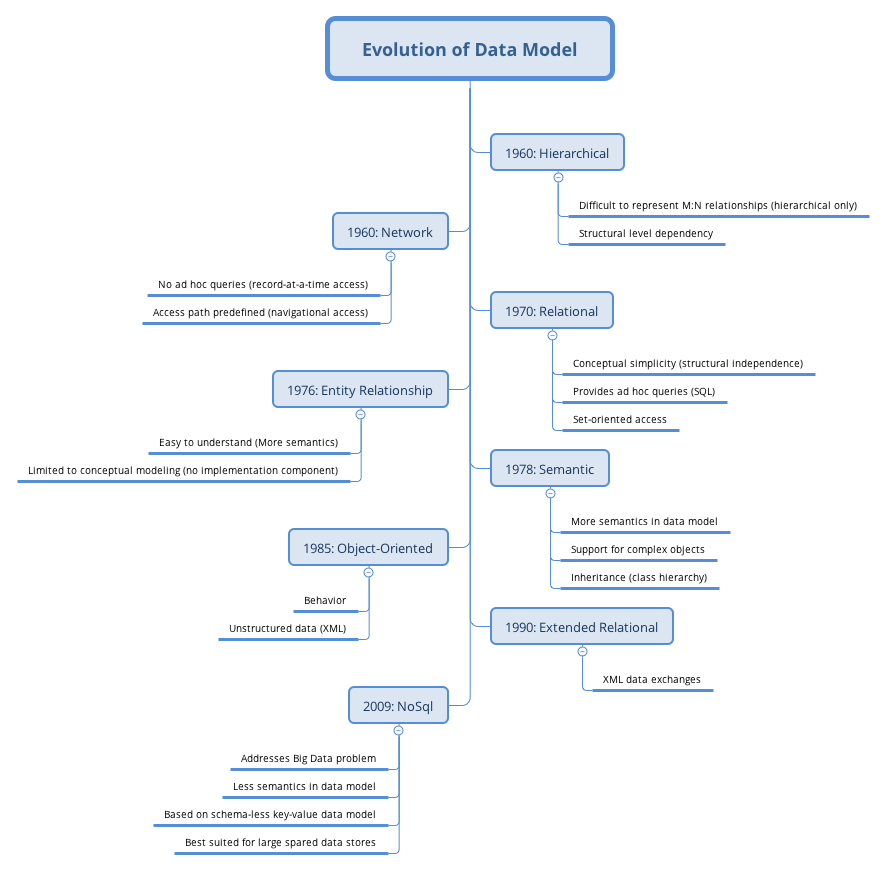
Here we will briefly talk a little about the relational and NoSql. Because we are going to work a lot with relational model. If you are interested in learning more, there is material widely available on the internet and you can do your own research.
The benefits of a relational model are:
- simplify the connections between the data
- allow you to write queries (retrieve/update/write data) easily
NoSQL was part of the Big Data movement that you should have already heard about. It is a mechanism for storage and retrieval where it’s not modeled in a tabular relational format. NoSQL was popular when big data and unstructured data first came out because you left it unstructured, but it’s now started to soften a little bit, and more commonly referred to as Not Only SQL. One question to think about: does SQL really have a role still in the Big Data world, as new things start to come out like NoSQL and unstructured data?
Next let’s talk about the difference between relational and transactional databases. A relational model is a database design that shows the relationships between the different tables, optimizes querying data, makes it easy and intuitive to access the data. Transactional model is a more operational database. If you are in healthcare, for example, you may have a transactional database that is used to store all the claims information and then this information may not be stored in a great way for querying and using it for analysis. In fact, you may need to take and extract that transactional information from the database and move it into a relational model.
Most of what we will be working with is the relational model. There are 3 building blocks for relational model:
- Entities: a person, place, thing or event. These are very distinguishable, unique and distict.
- Attributes: characteristics of this entity.
- Relationships: associations among different entities, can be one-to-many, many-to-many and one-to-one.
For example, Pioneer has a great corn seed product called P1197 which could be an entity. And then we have attributes that are characteristics of P1197, such as price, average yeilds, units sold, promotion programs. If you think of a one-to-many relationship, this could be P1197 has many promotion programs. When you think of a many-to-many relationship, this could be an example of many products to many different promotion programs. You may have one product that belongs to different programs or you may have a program that is available for different products. Then, if you think of a one-to-one relationship, it could be one product has a unique price.
To understand these relationships between the tables a lot better, what’s often used to depict this are ER diagrams. ER model is composed of entity types and specific relationships that can exist between instances of those entity types. These are usually displayed in a visual format and a relate represents a relationship between the tables. It often helps you to understand and represent a business process and it will show the links between these tables. The links are important when we join these tables. Being able to look at this diagram and see how they relate to each other is really important.
We can use the primary key or foreign key to join tables. The primary key is a column or set of columns whose values uniquely identify every row in a table. Foreign key is one or more columns can be used together to identify a single row in another table. When we’re looking at ER diagrams, which again is one of the ways you will start to think before you do, you’ll look at maybe an ER diagram and understand what data elements you are trying to join together and how do you need to get them. But one of the things you need to understand is how to read this. We talked a little bit about relationships and the different relationships between a table. There is a different type of notation that explains the relationships.
- Chen notation
- Crow’s foot notation
- UML class diagram notation
The Chen notation uses 1:M for a one-to-many relationship, and M:N for a many-to-many relationship and 1:1 for a one-to-one relationship.
In Crow’s foot notation, we have the train tracks which represent 1 and then the Crow’s foot which represents many.
In UML notation, we have a 1.1 which represents the concept of one and 1.* which represents the concept of many.
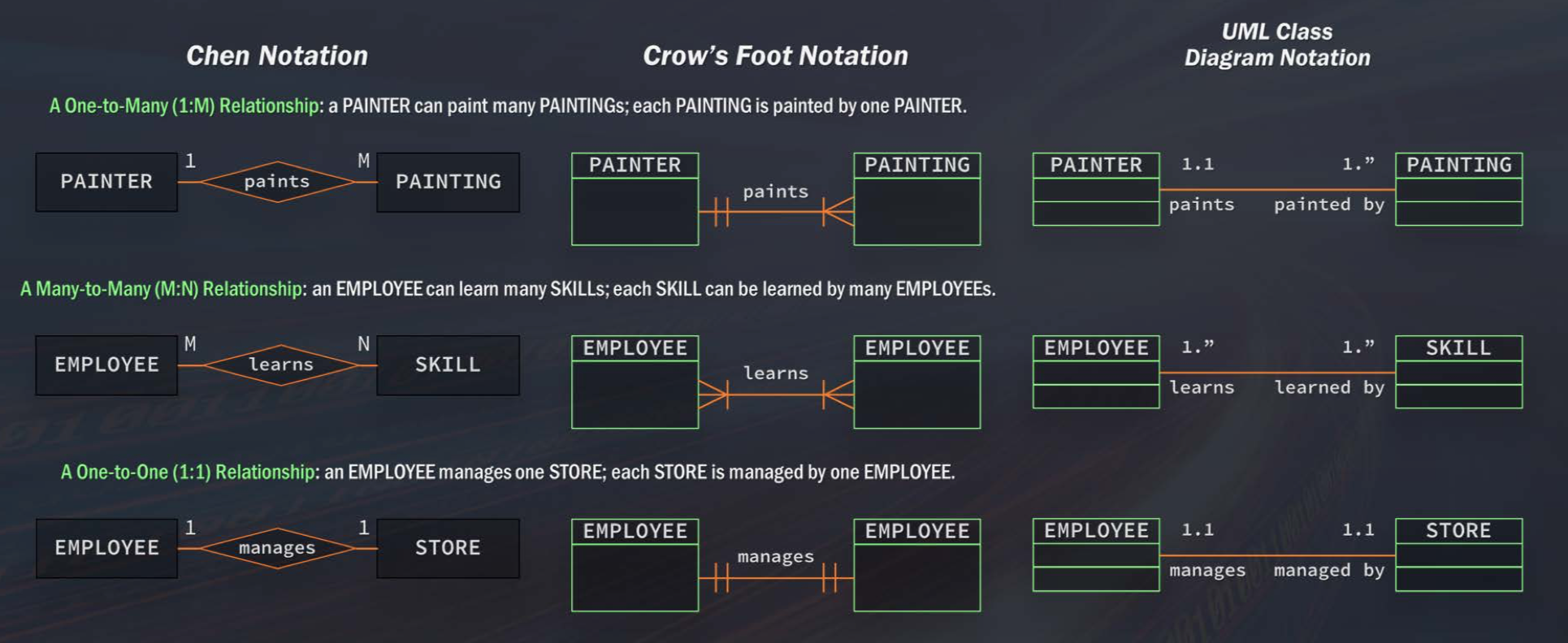
Get familar with the different notations since you’ll be looking at ER diagrams quite frequently and you’ll need to understand these notations when reading ER diagrams so you can understand how you’re going to write your query and join the table together or even to find out what’s listed in the table. Having a good understanding of why the data is structured in a particular way and how to read the ER diagrams is necessary for writing queries and ensuring accurate results.